새해에 블로그를 부활시켜보겠다고 다짐했는데, 벌써 반년이 지나고도 새 글이 없어서 좋은 글이라도 하나 번역해서 올려야겠다고 생각했다. 원문은 Drew Conway의 The Data Science Venn Diagram라는, 데이터 분석가들 사이에서는 나름 고전이 된 2010년의 (꽤 오래된) 글이다. 이 글에 등장한 다이어그램은 실제로 데이터 분석 또는 데이터 사이언스 관련 자료에서 꽤 빈번하게 등장하고, 나도 데이터마이닝에 관해 소개할 기회가 있으면 종종 사용한다. 마침 학기 말인데, 한 학기를 회고하는 시점에서 번역하기 적절한 자료라고도 판단했다.
이 글은 Drew의 허락을 받고 번역을 했으며, 내용을 매끄럽게 하기 위해 곳곳에서 의역을 했음을 밝힌다.
지난 월요일 나는 - 영광스럽게도 - 뉴욕시에서 데이터에 관한 한 가장 뛰어난 뇌들이 모인다는 반나절짜리 언컨퍼런스(unconference)에 참석했다. 이 행사는 오라일리(O’Reily)의 스트라타(Strata) 컨퍼런스를 준비하기 위한 것이었는데, 그 날 열린 소규모 세션(breakout session)들은 참석 인원이 적당해서 아주 뛰어난, 전문가적인 토론이 가능했다. 내가 참석한 세션 중 가장 좋았던 것은 데이터 사이언스의 교습법에 대한 것이었는데, 아니나 다를까 이 세션의 주제는 결국, 뛰어난 데이터 사이언티스트가 되기 위해 필요한 능력(skill)은 무엇인가에 대한 토론으로 이어지게 되었다.
전에도 이야기했지만, 나는 “데이터 사이언스"라는 용어는 잘못된 표현(misnomer)이라고 생각한다.1 하지만 이 토론을 마치고 나서 상당히 희망적인 생각을 가지게 되었는데, 그 이유는 우리가 데이터 사이언스라는 과목의 커리큘럼에 대한 아무런 합의를 이끌어내지 못했기 때문이다. 데이터 사이언티스트가 되기 위한 능력을 정의하는 것이 어려운 이유는, 워낙 실무(substance)와 방법론(methodology) 사이의 경계가 모호한데다가 해커, 통계학자, 도메인 전문가와 그들 사이의 교집합을 뚜렷하게 구분하면서 데이터 사이언스가 속하는 지점을 찾아내는 것이 쉽지 않기 때문이다.
다만 유일하게 명확한 것은 경쟁력 있는 데이터 사이언티스트가 되기 위해서 아주 많이 배워야한다는 것인데, 불행히도 교과서와 튜토리얼을 나열하는 것만으로는 거기에 별 도움이 되지 않는다. 따라서, 이미 너무 많은 의견이 오간 주제임에도 불구하고, 논란을 축소하고 내 생각을 덧붙이기 위해 데이터 사이언스 벤 다이어그램(Data Science Venn Diagram)을 소개한다.
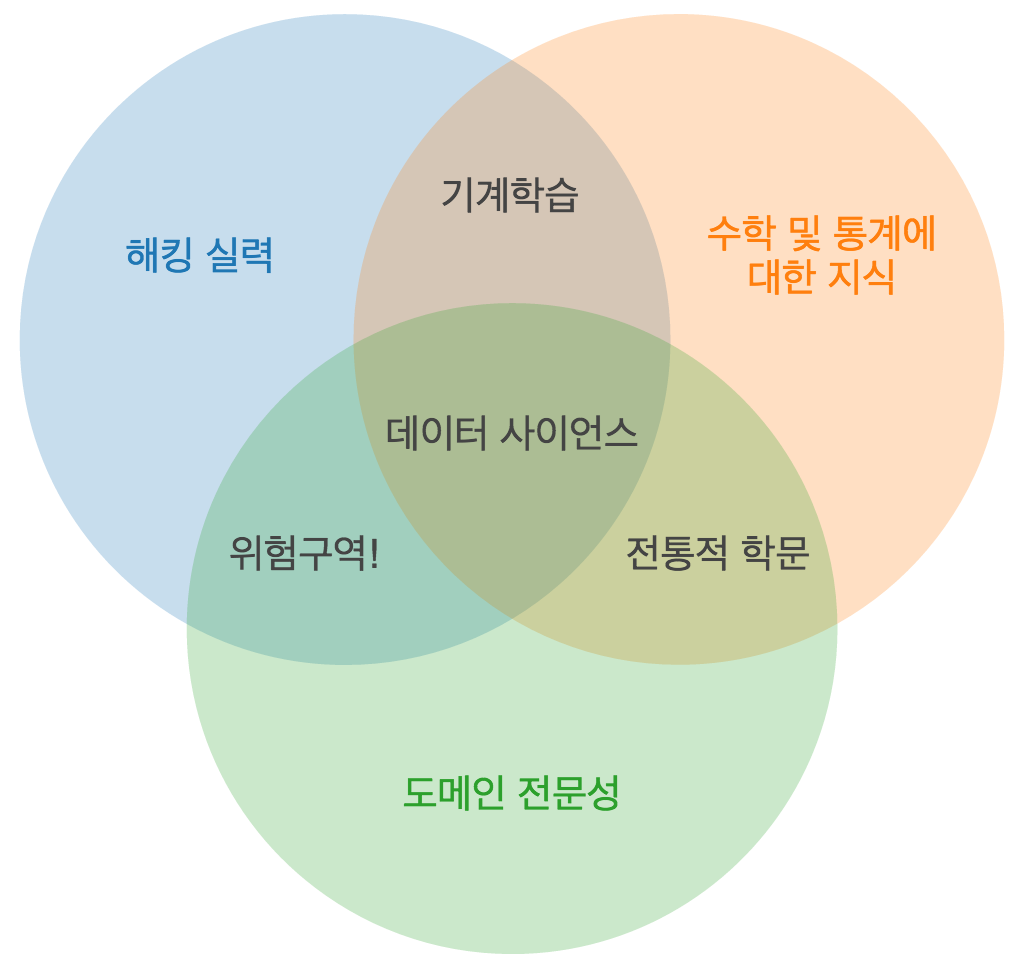
데이터 사이언스 벤 다이어그램 읽는 법
데이터의 3원색: 해킹 실력, 수학 및 통계에 대한 지식, 도메인 전문성 2
- 지난 월요일에 우리는 데이터 사이언스라는 강좌가 대학의 “어떤 학과"에서 열려야할지 토론하는데 많은 시간을 할애했다. 참석한 모두가 데이터 사이언스에 필요한 능력들이 얼마나 학제적(interdiciplinary)인지 이해하고 있었기 때문에 토론은 다분히 수사적이었다. 그런데 하필 위의 세 가지 항목을 택한 이유는 다음과 같다. 첫째, 셋 모두 특정 학과와 무관하다. 둘째, 각 영역은 독립적으로도 아주 가치있지만, 세 가지 중 두 가지만 결합되었을 때는 데이터 사이언스가 아닐 뿐더러 경우에 따라 아주 위험한 선택이 될 수도 있는 것들이다.
- 좋든 싫든 데이터는 전자적으로(electronically) 거래되는 재화(commodity)이다. 따라서 이 시장에 참여하기 위해서는 프로그래밍을 좀 해야한다. 그렇다고 컴퓨터 공학을 전공해야 한다는 것은 아니다. 실제로 내가 아는 뛰어난 해커 몇명은 컴공 수업을 단 한 개도 들어본 적이 없다. 성공적인 데이터 해커가 된다는 것은 텍스트 파일을 명령줄(command line)에서 조작할 줄 알고, 벡터 연산을 이해하고, 알고리즘적으로 사고하는 등의 것을 말한다.
- 일단 데이터를 수집하고 정제했다면 다음 단계는 데이터에서 인사이트(insight)를 이끌어내는 것이다. 이를 위해서는 적절한 수학 및 통계학적 방법론을 적용하고, 그에 대한 최소한의 이해는 할 수 있어야 한다. 경쟁력 있는 데이터 사이언티스트가 되기 위해서 반드시 통계학 박사학위가 있어야 한다는 말은 아니지만, 적어도 최소자승법 회귀분석(ordinary least squares regression)이 무엇이고, 그것을 어떻게 해석해야하는지는 알아야 한다.
- 마지막 조각인 도메인 전문성은 이 주제에 대한 다른 사람들의 주장과 가장 큰 차이를 보이는 부분이다. 나는 데이터와 수학/통계의 결합은 기계학습(machine learning)밖에 되지 못한다고 생각한다. 당신의 관심 분야가 그것이라면 다행이지만, 데이터 사이언스라면 그렇지 않다. 사이언스, 즉 과학이란 원래 세상에 대한 흥미로운 질문이나 가설을 던진 후 데이터를 수집해서 통계적 방법론으로 검증하여 지식을 발견하고 쌓아나가는 것이다. 도메인 전문성과 수학 및 통계적 지식의 교집합은 대부분의 전통적인 학문이 속하는 영역이다. 많은 박사급 연구자들은 이 구역에서 전문성을 쌓는데 자기 시간의 대부분을 할애하며, 기술(technology) 습득에는 시간을 많이 투자하지 않는다. 이러한 성향은 연구자들의 기술 이해 수준에 대한 보상을 하지 않는 학계의 특성 때문이기도 하다. 물론, 나는 그런 전통을 타계하고자하는 젊은 학자 또는 대학원생도 많이 만났다.
- 마지막으로, 해킹 실력과 도메인 전문성의 결합에 대한 의견은 다음과 같다. 이 영역에 속하는 사람들은 “아는 것이 해"가 되는 부류이며, 이 영역은 다이어그램에서 가장 문제가 되는 부분이다. 이 영역에 속하는 사람들은 자기가 적당히 아는 분야에 대해 스스로 데이터를 추출하거나 구조화할 수 있고, R도 적당히 알아서 회귀분석 계수도 보고할 수 있지만 그 계수들의 의미에 대해서는 제대로 알지 못한다. 바로 이 영역의 사람들은, 몰라서, 혹은 숨겨진 다른 의도 때문에, 자신들이 어떤 과정으로 무엇을 만들었는지도 모른 채, 겉으로는 마치 적법해보이는 분석 결과를 보이며 “거짓말, 망할 거짓말, 그리고 통계학(lies, damned lies, and statistics)” 따위의 말들이 세상에 존재하는 이유가 된다. 다행히도, 수학 및 통계적 지식을 전혀 습득하지 않으면서 해킹 실력과 도메인 전문성을 동시에 쌓아나가는 것은 쉬운 일이 아니기 때문에 이 부분에 속하는 사람은 그리 많지 않다. 한편, 재앙을 만드는데는 많은 사람이 필요하지 않기도 하다.
데이터 사이언스가 무언인지, 데이터 사이언티스트가 되기 위해서는 어떻게 해야하는지에 대해 내 설명이 도움이 되었으면 한다. 이러한 질문들에 대해 거시적인 답을 내리려는 시도는 논의가 지나치게 미시적인 것, 즉 세세한 도구나 플랫폼 따위에 대한 토론으로 번지는 것을 방지한다고 생각한다.
물론 내가 많은 중요한 부분을 놓쳤을 수 있다. 그런데 다시 한번 말하지만 구체적인 그림을 그리는 것이 목적이 아니었음을 말하고 싶다. 언제나 그렇듯, 어떠한 코멘트도 대환영이다.
-
2015년 6월 기준으로 이 문장에서 원문의 링크 두 개는 동작하지 않는데, 대신 “데이터 사이언스란 무엇인가?“라는 질문에 대한 이 답변을 보면 Drew가 왜 데이터 사이언스가 잘못된 표현이라고 생각하는지 엿볼 수 있다. ↩︎
-
원문에서는 domain expertise이라는 표현 대신 substantive expertise라는 표현을 사용했다. ↩︎