Pre-데이터마이너로서 난 아직 그리 많은 empirical한 데이터를 다뤄보진 않았지만 어떤 모델을 적용하느냐, 결과가 좋으냐 나쁘냐보다 중요시해야할 궁극의 질문은 데이터 선택의 문제가 아닌가 싶다.
즉, 나의 목적에 어떤 데이터가 필요한지 파악한 후 내가 실제로 가지고 있는 데이터는 그 기준을 만족하는지 판단하는 것이다. 판단에는 두 가지 과정이 있을 수 있는데, 그것은:
- 내가 가지고 있는 데이터에서 목적에 불필요한 데이터를 제하는 과정과 (data reduction)
- 내가 가지고 있지 않지만 목적에 필요한 데이터를 더하는 과정이다 (data production).
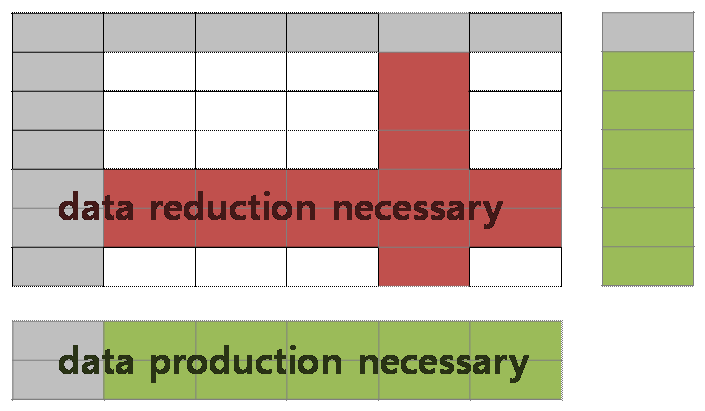
Data reduction
Feature selection, variable selection 등의 방식이 있고, PCA, ICA처럼 데이터 자체를 변형할 수도 있다. 생각해보면 사람도 복잡한 상황에서 필요한 변수들만 고려하며 의사결정을 내리곤 한다.
Example: 루시는 ‘과연 유학을 갈 것인가’하는 질문에 대해 훗날 가지고자 하는 직업, 사회적 인식, 학업적 기대, 지도교수의 선택, 남자친구와의 관계, 나이, 인생관, 가치관, 성격, 선배들으 조언 등 수많은 변수들을 고려하며 결정을 내리고자 한다. 그렇지만 아무래도 변수들 간의 correlation, 게다가 문제를 더욱 복잡하게 만다는 causal relationship들은 그녀를 더욱 골치 아프게 한다. 그래서 그녀는 결국 가장 중요한 다섯개의 변수들만 고려하기로 한다(variable selection). 그리고 수많은 사례 중에서 같은 연구실 출신의 유학 간 여자 선배들의 사례들만 보고, 유학을 갈 것인지 말 것인지를 결정하기로 한다.
Data production 1
가지고 있는 데이터가 너무 적은 경우, bootstrapping과 같은 특이한 sampling 기법을 사용하여 가지고 있는 데이터를 뻥튀기 시키기도 한다. 혹은 unlabeled data의 labeling의 문제, 혹은 missing value를 추정하는 여러가지 기법들이 있을 수 있다.
Example (cont.): 루시는 그녀와 가장 유사한, ‘같은 연구실 출신의 유학 간 여자 선배들의 사례’를 참고하여 가장 성공한 사례를 모방(그 모델에 스스로를 scoring)하고자 한다. 그러나 여기서 발생한 문제! 일단 위의 조건을 만족하는 선배의 수가 매우 극소수였던 것이다! 그렇다면 여기서 그녀가 하고 싶은 것은, 새로운 data의 reproduction, 내지는 discovery이다. 어떻게 하면 유사한 사례를 더 찾을 수 있을까? 게다가 어떻게 하면, “성공"을 객관적으로 측정할 수 있을까?
-
Or creation. ↩︎